eBPF map Introduction
先前在简单的 eBPF 版本的 Hello eBPF World程序中向用户态程序传递信息使用的是 bpf_trace_printk(),这种方式有局限性:它只能单向通信、参数最多为三个。另一种通信手段 eBPF map,则没有上述限制,它被设计成 key/value 的形式,能够在用户态程序与内核态 eBPF 程序之间进行双向通信。官方描述 [1]:
Maps are a generic data structure for storage of different types of data. They allow sharing of data between eBPF kernel programs, and also between kernel and user-space applications. eBPF map 在使用时有四个参数需要设置:
- type: eBPF map 的类型,最基础的两类是
array与hash,区别在于前者预分配空间,后者用时分配 - key_size: key 的字节大小
- value_size: value 的字节大小
- max_entries: 元素的最大数量 eBPF map 通过 bpf() 对用户态程序提供了五类 cmd [1];对于 eBPF 程序,bpf-helpers 也列出了可用的 bpf call [2]:
#bpf() cmd
BPF_MAP_CREATE
BPF_MAP_LOOKUP_ELEM
BPF_MAP_UPDATE_ELEM
BPF_MAP_DELETE_ELEM
BPF_MAP_GET_NEXT_KEY
#bpf call
#通用
bpf_map_lookup_elem()
bpf_map_update_elem()
bpf_map_delete_elem()
#perf event array 专用
bpf_perf_event_{read, read_value}()
bpf_perf_event_output()
#ring buffer 专用
bpf_ringbuf_output()
bpf_ringbuf_reserve()
bpf_ringbuf_submit()
bpf_ringbuf_discard()
bpf_ringbuf_query()
在本文中,介绍使用 socket eBPF 在 socket 层面完成本地socket转发的逻辑,消除了逐报文 NAT 转换处理,进一步提升socket报文的转发性能。

BPF 基础
通常情况下,eBPF 程序由两部分构成:
- 内核空间部分:内核事件触发执行,例如网卡收到一个包、系统调用创建了一个 shell 进程等等;
- 用户空间部分:通过某种共享数据的方式(例如 BPF maps)来读取内核部分产生的数据; 本文主要关注内核部分。内核支持不同类型的 eBPF 程序,它们各自可以 attach 到不同的 hook 点,如下图所示:
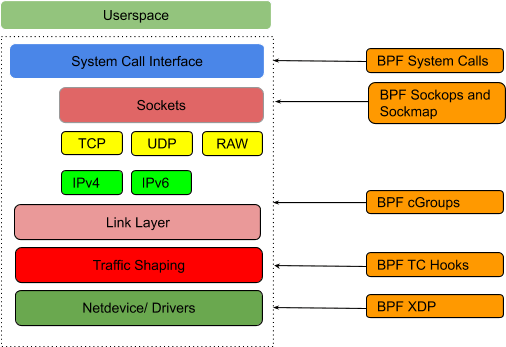
当内核中触发了与这些 hook 相关的事件(例如,发生 setsockopt()系统调用)时, attach 到这里的 BPF 程序就会执行。
用户侧需要用到的所有 BPF 类型都定义在 UAPI bpf.h。 本文将主要关注下面两种能拦截到 socket 操作(例如 TCP connect、sendmsg 等)的类型:
BPF_PROG_TYPE_SOCK_OPS:socket operations 事件触发执行。
BPF_PROG_TYPE_SK_MSG:sendmsg() 系统调用触发执行。
BPF 程序设计
首先创建一个全局eBPF map来记录所有的 socket 信息。基于这个 sockmap,编写两段 BPF 程序分别完成以下功能:
BPF程序一:拦截所有 TCP connection 事件,然后将 socket 信息存储到这个 eBPF map; BPF程序二:拦截所有 sendmsg() 系统调用,然后从 map 中查 询这个socket 信息,之后直接将数据重定向到对端。
BPF 程序一:监听 socket 事件,更新sockmap
__section("sockops")
int bpf_sockmap(struct bpf_sock_ops *skops)
{
switch (skops->op) {
case BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB:
case BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB:
//#define AF_INET 2 /* Internet IP Protocol */
//#define AF_INET6 10 /* IP version 6 */
if (skops->family == 2)
bpf_sock_ops_ipv4(skops);
else if (skops->family == 10)
bpf_sock_ops_ipv6(skops);
break;
default:
break;
}
return 0;
}
对于sock报文地址都在本节点的 socket 来说,这段代码会执行两次:
- 源端发送 SYN 时会产生一个事件,命中
case BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB主动建立连接 - 目的端发送 SYN+ACK 时会产生一个事件,命中
case BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB被动建立连接
因此对于每一个成功建连的 socket,sockmap 中会有两条记录(key 不同)。
将 socket 信息存入 sockmap
static inline
void bpf_sock_ops_ipv4(struct bpf_sock_ops *skops)
{
struct sock_key key = {};
int ret;
sk_extract4_key_from_ops(skops, &key);
// See whether the source or destination IP is local host
//127.0.0.1 ==>7f 00 00 01 ==>01 00 00 7F ==>16777343(=1*256^3+7*16+15)
if (key.dip4 == 16777343 || key.sip4 == 16777343 ) {
// See whether the source or destination port is 10000
if (key.dport == 4135 || key.sport == 4135) {
ret = sock_hash_update(skops, &sock_ops_map, &key, BPF_NOEXIST);
printk("<<< ipv4 op = %d, port %d --> %d\n", skops->op, key.sport, key.dport);
if (ret != 0)
printk("*** FAILED %d ***\n", ret);
}
}
}
这部分逻辑分三个步骤:
- 调用
sk_extract4_key_from_ops()从struct bpf_sock_ops *skops(socket metadata)中提取 key; - 调用 sock_hash_update() 将 key:value 写入全局的 sockmap sock_ops_map,这个sockmap变量定义在我们的头文件中。
- 打印一行日志,用于排查报错信息。
全局 sockmap sock_ops_map
struct bpf_map_def __section("maps") sock_ops_map = {
.type = BPF_MAP_TYPE_SOCKHASH,
.key_size = sizeof(struct sock_key),
.value_size = sizeof(int),
.max_entries = 65535,
.map_flags = 0,
};
sock_key 定义:
struct sock_key {
union {
struct {
__u32 sip4;
__u32 pad1;
__u32 pad2;
__u32 pad3;
};
union v6addr sip6;
};
union {
struct {
__u32 dip4;
__u32 pad4;
__u32 pad5;
__u32 pad6;
};
union v6addr dip6;
};
__u8 family;
__u8 pad7; // this padding required for 64bit alignment
__u16 pad8; // else ebpf kernel verifier rejects loading of the program
__u32 sport;
__u32 dport;
} __attribute__((packed));
提取key meta信息
static inline
void sk_extract4_key_from_ops(struct bpf_sock_ops *ops, struct sock_key *key)
{
key->dip4 = ops->remote_ip4;
key->sip4 = ops->local_ip4;
key->family = 1;
key->sport = (bpf_htonl(ops->local_port) >> 16);
key->dport = ops->remote_port >> 16;
}
插入 sockmap
sock_hash_update() 将 socket 信息写入到 sockmap,具体实现不展开。
至此,BPF程序一代码就完成了,它能确保我们拦截到 socket 建连的2个case事件,并将 socket 信息写入一个全局的eBPF map(sockmap)。
BPF 程序二:拦截 sendmsg 系统调用,socket 重定向
第二段 BPF 程序二的功能:
- 拦截所有的
sendmsg系统调用,从消息中提取key; - 根据
key查询sockmap,找到这个 socket 的对端,然后绕过TCP/IP 协议栈,直接将 数据重定向过。 要完成这个功能,需要:
在 socket 发起 sendmsg 系统调用时触发执行,
指定加载位置来实现:__section("sk_msg")
关联到前面已经创建好的 sockmap,因为要去里面查询 socket 的对端信息。
通过将 sockmap attach 到 BPF 程序实现:map 中的所有 socket 都会继承这段程序, 因此其中的任何 socket 触发 sendmsg 系统调用时,都会执行到这段代码。
BPF 程序二:bpf_redir拦截 sendmsg 系统调用,socket 重定向
__section("sk_msg")
int bpf_redir(struct sk_msg_md *msg)
{
struct sock_key key = {};
sk_msg_extract4_key_from_msg(msg, &key);
// See whether the source or destination IP is local host
if (key.sip4 == 16777343 || key.dip4 == 16777343) {
// See whether the source or destination port is 10000
if (key.sport == 4135 || key.dport == 4135) {
//int len1 = (__u64)msg->data_end - (__u64)msg->data;
//printk("<<< redir_proxy port %d --> %d (%d)\n", key.sport, key.dport, len1);
msg_redirect_hash(msg, &sock_ops_map, &key, BPF_F_INGRESS);
}
}
//**SK_PASS** on success, or **SK_DROP** on error.
return SK_PASS;
}
当内核attach了这段程序的 socket 上有 sendmsg 系统调用时,内核就会执行这段代码。它会
- 从sock metadata中提取key
- 判断
key.sip4是否等于127.0.0.1或者key.dip4是否等于127.0.0.1,判断key.sportkey.dport是否等于1000 - 对于满足上述条件2之后,调用 bpf_socket_redirect_hash() 寻找对应的 socket,并根据 flag(BPF_F_INGRESS), 将数据重定向到 socket 的相应queue。
从 socket message 中提取 key
static inline
void sk_msg_extract4_key_from_msg(struct sk_msg_md *msg, struct sock_key *key)
{
key->sip4 = msg->remote_ip4;
key->dip4 = msg->local_ip4;
key->family = 1;
key->dport = (bpf_htonl(msg->local_port) >> 16);
key->sport = msg->remote_port >> 16;
}
socket重定向
msg_redirect_hash() 也是我们定义的一个宏,最终调用的是 BPF 内置的辅助函数。
static int BPF_FUNC(msg_redirect_hash, struct sk_msg_md *md, void *map, void *key, uint64_t flags);
最终需要用的其实是内核辅助函数 bpf_msg_redirect_hash(),但后者无法直接访问, 只能通过 UAPI linux/bpf.h预定义的 BPF_FUNC_msg_redirect_hash 来访问,否则校验器无法通过。
msg_redirect_hash(msg, &sock_ops_map, &key, BPF_F_INGRESS) 几个参数:
struct sk_msg_md *msg:用户可访问的待发送数据的元信息(metadata)&sock_ops_map:这个 BPF 程序 attach 到的 sockhash mapkey:在 map 中索引用的 keyBPF_F_INGRESS:放到对端的哪个 queue(rx 还是 tx)
编译、加载、运行
编译
用 LLVM Clang frontend 来编译前面两段程序,生成目标代码(object code):
# Compile the bpf_sockops and bpf_redir program
clang -O2 -g -Wall -target bpf -c bpf_sockops.c -o bpf_sockops.o
clang -O2 -g -Wall -target bpf -c bpf_redir.c -o bpf_redir.o
加载
# Load the bpf_sockops program
sudo bpftool prog load bpf_sockops.o "/sys/fs/bpf/bpf_sockop"
Attach到cgroup
sudo bpftool cgroup attach "/sys/fs/cgroup/" sock_ops pinned "/sys/fs/bpf/bpf_sockop"
- 这条命令将加载之后的 sock_ops 程序 attach 到指定的 cgroup,
- 这个 cgroup 内的所有进程的所有 sockets,都将会应用这段程序。
如果Ubuntu 22.04使用的是 cgroupv2 时,systemd 会在 /sys/fs/cgroup自动创建一个mount 点。
$ mount | grep cgroup
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
获取 MAP ID
MAP_ID=$(sudo bpftool prog show pinned "/sys/fs/bpf/bpf_sockop" | grep -o -E 'map_ids [0-9]+' | awk '{print $2}')
至此,eBPF代码已经加载(load)和附着(attach)到 hook 点了,接下来查看 sock_ops 程序所使用的 MAP ID,因为后面要用这个 ID 来 attach sk_msg 程序:
加载和 attach sk_msg 程序
sudo bpftool prog load bpf_redir.o "/sys/fs/bpf/bpf_redir" map name sock_ops_map pinned "/sys/fs/bpf/sock_ops_map"
sudo bpftool prog attach pinned "/sys/fs/bpf/bpf_redir" msg_verdict pinned "/sys/fs/bpf/sock_ops_map"
查看统中已加载的所有 BPF 程序
...
261: sock_ops name bpf_sockmap tag 3d34e7b6348f14a9 gpl
loaded_at 2022-11-28T16:59:27+0800 uid 0
xlated 1240B jited 725B memlock 4096B map_ids 11
btf_id 179
265: sk_msg name bpf_redir tag a5774cb7cff96661 gpl
loaded_at 2022-11-28T16:59:27+0800 uid 0
xlated 304B jited 196B memlock 4096B map_ids 11
btf_id 185
...
查看系统中map,以及 map sock_ops_map详情
$ sudo bpftool map show
...
11: sockhash name sock_ops_map flags 0x0
key 44B value 4B max_entries 65535 memlock 3145728B
$ sudo bpftool -p map show id 11 // -p/--pretty:人类友好格式打印
{
"id": 11,
"type": "sockhash",
"name": "sock_ops_map",
"flags": 0,
"bytes_key": 44,
"bytes_value": 4,
"max_entries": 65535,
"bytes_memlock": 3145728,
"frozen": 0
}
测试tracing
#Run iperf3 server on loaclhost and port 1000
iperf3 -s -B 127.0.0.1 -p 10000
#Run iperf3 client
iperf3 -c 127.0.0.1 -t 10 -l 64k -p 10000
#Collect tracing
sudo cat /sys/kernel/debug/tracing/trace_pipe
iperf3-274366 [000] d...1 871864.972580: bpf_trace_printk: <<< ipv4 op = 4, port 12419 --> 4135
iperf3-274366 [000] d.s11 871864.972600: bpf_trace_printk: <<< ipv4 op = 5, port 4135 --> 12419
<...>-274382 [000] d...1 871892.891839: bpf_trace_printk: <<< ipv4 op = 4, port 36036 --> 4135
<...>-274382 [000] d.s11 871892.891857: bpf_trace_printk: <<< ipv4 op = 5, port 4135 --> 36036
<...>-274384 [000] d...1 871893.691838: bpf_trace_printk: <<< ipv4 op = 4, port 38596 --> 4135
<...>-274384 [000] d.s11 871893.691855: bpf_trace_printk: <<< ipv4 op = 5, port 4135 --> 38596
<...>-274385 [003] d...1 871894.215995: bpf_trace_printk: <<< ipv4 op = 4, port 40644 --> 4135
iperf3-274385 [003] d.s11 871894.216039: bpf_trace_printk: <<< ipv4 op = 5, port 4135 --> 40644
清理
# UnLoad the bpf_redir program
sudo bpftool prog detach pinned "/sys/fs/bpf/bpf_redir" msg_verdict pinned "/sys/fs/bpf/sock_ops_map"
sudo rm "/sys/fs/bpf/bpf_redir"
# UnLoad the bpf_sockops program
sudo bpftool cgroup detach "/sys/fs/cgroup/" sock_ops pinned "/sys/fs/bpf/bpf_sockop"
sudo rm "/sys/fs/bpf/bpf_sockop"
# Delete the map
sudo rm "/sys/fs/bpf/sock_ops_map"
结束语
本文介绍使用 socket eBPF 在 socket 层面完成本地socket转发的逻辑,绕过TCP/IP协议,消除了报文 NAT 转换处理,进一步提升socket报文的转发性能。
参考文档
http://arthurchiao.art/blog/socket-acceleration-with-ebpf-zh/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#11-bpf-%E5%9F%BA%E7%A1%80 https://github.com/torvalds/linux/blob/master/include/uapi/linux/bpf.h https://students.mimuw.edu.pl/SO/Linux/Kod/include/linux/socket.h.html https://github.com/zachidan/ebpf-sockops https://vvl.me/2021/02/eBPF-3-eBPF-map/