背景
最近由于kubernetes的版本更新比较频繁,看着自己的集群还是version 1.13.3版本,就想着升级到1.14.6 目前为止的最新版本,核心组件的升级还是没有什么问题,由于本身是二进制形式安装,升级还是比较简单
还有一个主要的目的:
etcd的版本升级到3.4版本 进行比较大的性能和稳定性的优化 CHANGELOG
核心组件的相关监控就必不可少,接下来就在集群环境中部署prometheus-operator 用的是helm包安装
简单粗暴
helm install stable/prometheus-operator --namespace monitoring -f value.yaml
由于etcd是由单独的外部集群3台vm搭建,prometheus-operator在监控etcd的target时候需要指定证书然后https的形式访问
这样就需要提前创建secret 并修改value.yaml 中kubeEtcd serviceMonitor部分
D="$(mktemp -d)"
cp /etc/kubernetes/ssl/{ca,kubernetes,kubernetes-key}.pem $D
kubectl create ns monitoring
kubectl -n monitoring create secret generic etcd-client --from-file="$D"
rm -fr "$D"
...
kubeEtcd:
serviceMonitor:
scheme: https
insecureSkipVerify: true
caFile: /etc/prometheus/secrets/etcd-client/ca.pem
certFile: /etc/prometheus/secrets/etcd-client/kubernetes.pem
keyFile: /etc/prometheus/secrets/etcd-client/kubernetes-key.pem
prometheus:
prometheusSpec:
secrets:
- etcd-client
...
以上的都弄好之后,slack的#AlertManager的channel的一条告警引起的我的注意
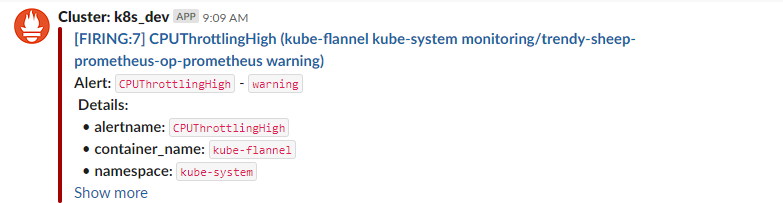
prometheus alert rule
alert: CPUThrottlingHigh
expr: 100
* sum by(container_name, pod_name, namespace) (increase(container_cpu_cfs_throttled_periods_total{container_name!=""}[5m]))
/ sum by(container_name, pod_name, namespace) (increase(container_cpu_cfs_periods_total[5m]))
> 25
for: 15m
pod resources in metrics-server
root@k8s-master-1:~# kubectl top pod -n kube-system | grep kube-flannel-ds-amd64
NAME CPU(cores) MEMORY(bytes)
kube-flannel-ds-amd64-72hfh 8m 12Mi
kube-flannel-ds-amd64-cpklp 3m 13Mi
kube-flannel-ds-amd64-d5rvg 3m 13Mi
kube-flannel-ds-amd64-fcjwm 3m 11Mi
kube-flannel-ds-amd64-ljpjk 3m 11Mi
kube-flannel-ds-amd64-lqx7x 4m 13Mi
kube-flannel-ds-amd64-n9vzr 3m 13Mi
This pod has one container with these resources setup (Guaranteed Qos ):
Limits:
cpu: 100m
memory: 50Mi
Requests:
cpu: 100m
memory: 50Mi
一切看上去都好像没什么问题,我还是用关键字搜索下有没有其他人碰到类似的问题
查到一些issue
https://devops.stackexchange.com/questions/6494/prometheus-alert-cputhrottlinghigh-raised-but-monitoring-does-not-show-it
https://kubernetes.io/zh/docs/tasks/administer-cluster/cpu-management-policies/
The
CPUThrottlingHighis an alert created by the kubernetes-mixin project. There is an open issue (#108) to discuss this alert. I suggest that you read all the comments on this issue to better understand the problem.In short, the problem is: When working with low CPU limits, spiky workloads can have low averages and still be being throttled.
Also, take a look at this issue (#67577) from Kubernetes project, which addresses a Kernel bug in CFS quotas that may cause unnecessary CPU throttling. The discussion is still open, and the Kubernetes project are even considering disabling CFS quotas for pods in the
GuaranteedQoS (see #70585 for reference).Consider the following options:
- Increase (or even remove) your container CPU limits
- Disable Kubernetes CFS quotas entirely (kubelet’s flag
--cpu-cfs-quota=false)
这个issue给了2个解决方案
- limits 对cpu 不做限制
Limits: memory: 50Mi Requests: cpu: 100m memory: 50Mi - kubelet 运行新增参数
--cpu-cfs-quota=false
还有一种就是忽略这个CPUThrottlingHigh告警
route:
routes:
- match:
alertname: 'CPUThrottlingHigh'
receiver: 'silent-receiver'
receivers:
- name: silent-receiver
CPU 管理策略
默认情况下,kubelet 使用 CFS 配额 来执行 pod 的 CPU 约束。当节点上运行了很多 CPU 密集的 pod 时,工作负载可能会迁移到不同的 CPU 核,这取决于调度时 pod 是否被扼制,以及哪些 CPU 核是可用的。许多工作负载对这种迁移不敏感,因此无需任何干预即可正常工作。
配置
CPU 管理器(CPU Manager)作为 alpha 特性引入 Kubernetes 1.8 版本。 必须在 kubelet 特性开关中显式启用: --feature-gates=CPUManager=true。
CPU 管理策略通过 kubelet 参数 --cpu-manager-policy 来指定, 有两种支持策略:
none:默认策略,表示现有的调度行为。static:允许为节点上具有某些资源特征的 pod 赋予增强的 CPU 亲和性和独占性。
CPU管理器定期通过 CRI 写入资源更新,以保证内存中 CPU 分配与 cgroupfs 一致。同步频率通过新增的 Kubelet 配置参数 --cpu-manager-reconcile-period 来设置。 如不指定,默认与 --node-status-update-frequency 的周期相同。
None 策略
none 策略显式地启用现有的默认 CPU 亲和方案,不提供操作系统调度器默认行为之外的亲和性策略。 通过 CFS 配额来实现 Guaranteed pods 的 CPU 使用限制。
Static 策略
static 策略针对具有整数型 CPU requests 的 pod ,它允许该类 pod 中的容器访问节点上的独占 CPU 资源。这种独占性是使用 cpuset cgroup 控制器 来实现的。
Note: 注意: 诸如容器运行时和 kubelet 本身的系统服务可以继续在这些独占 CPU 上运行。独占性仅针对其他 pod。
Note: 注意: 该策略的 alpha 版本不保证 Kubelet 重启前后的静态独占性分配。
该策略管理一个共享 CPU 资源池,最初,该资源池包含节点上所有的 CPU 资源。可用的独占性 CPU 资源数量等于节点的 CPU 总量减去通过 --kube-reserved 或 --system-reserved 参数保留的 CPU 。通过这些参数预留的 CPU 是以整数方式,按物理内核 ID 升序从初始共享池获取的。 共享池是 BestEffort 和 Burstable pod 运行的 CPU 集合。Guaranteed pod 中的容器,如果声明了非整数值的 CPU requests ,也将运行在共享池的 CPU 上。只有 Guaranteed pod 中,指定了整数型 CPU requests 的容器,才会被分配独占 CPU 资源。
Note: 注意: 当启用 static 策略时,要求使用
--kube-reserved和/或--system-reserved来保证预留的 CPU 值大于零。 这是因为零预留 CPU 值可能使得共享池变空。
当 Guaranteed pod 调度到节点上时,如果其容器符合静态分配要求,相应的 CPU 会被从共享池中移除,并放置到容器的 cpuset 中。因为这些容器所使用的 CPU 受到调度域本身的限制,所以不需要使用 CFS 配额来进行 CPU 的绑定。换言之,容器 cpuset 中的 CPU 数量与 pod 规格中指定的整数型 CPU limit 相等。这种静态分配增强了 CPU 亲和性,减少了 CPU 密集的工作负载在节流时引起的上下文切换。
考虑以下 Pod 规格的容器:
spec:
containers:
- name: nginx
image: nginx
该 pod 属于 BestEffort 服务质量类型,因为其未指定 requests 或 limits 值。 所以该容器运行在共享 CPU 池中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
该 pod 属于 Burstable 服务质量类型,因为其资源 requests 不等于 limits, 且未指定 cpu 数量。所以该容器运行在共享 CPU 池中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
requests:
memory: "100Mi"
cpu: "1"
该 pod 属于 Burstable 服务质量类型,因为其资源 requests 不等于 limits。所以该容器运行在共享 CPU 池中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
requests:
memory: "200Mi"
cpu: "2"
该 pod 属于 Guaranteed 服务质量类型,因为其 requests 值与 limits相等。 同时,容器对 CPU 资源的限制值是一个大于或等于 1 的整数值。所以,该 nginx 容器被赋予 2 个独占 CPU。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "1.5"
requests:
memory: "200Mi"
cpu: "1.5"
该 pod 属于 Guaranteed 服务质量类型,因为其 requests 值与 limits相等。但是容器对 CPU 资源的限制值是一个小数。所以该容器运行在共享 CPU 池中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
该 pod 属于 Guaranteed 服务质量类型,因其指定了 limits 值, 同时当未显式指定时,requests 值被设置为与 limits 值相等。同时,容器对 CPU 资源的限制值是一个大于或等于 1 的整数值。所以,该 nginx 容器被赋予 2 个独占 CPU。