target发现失败
Kube-Scheduler和Kube-Controller-manager
最近在自己的Kubernetes集群版本用Kubespary做集群升级从1.17.4升级到1.17.9版本,主要对Kubernetes的组件包括 Kube-Apiserver、Kube-Scheduler、Kube-Controller-Manager、Kube-Proxy、Kubelet
在升级完之后,在之前用来接收告警信息的Slack的Alertmanger频道,收到告警信息
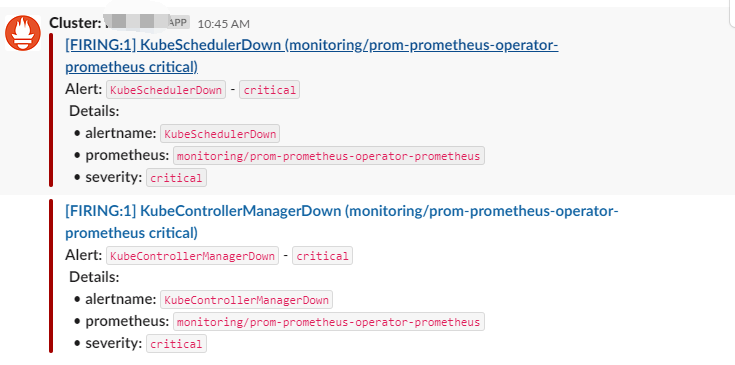
看了Details信息之后,登陆到Prometheus的管理界面看到,这2个组件的Target是Down的,提示信息:
Get http://192.168.2.10:10251/metrics: dial tcp 192.168.2.10:10251: connect: connection refused
看到这个信息,我的第一反应在kube-system命名空间里,有关于这2个组件的endpoints被重置或者由于升级集群的原因配置被丢失。
然后我看了下这部配置,并没有丢失
...
k get ep -n kube-system -l k8s-app=kube-controller-manager
NAME ENDPOINTS AGE
prom-prometheus-operator-kube-controller-manager 192.168.2.10:10252,192.168.2.11:10252 23h
k get ep -n kube-system -l k8s-app=kube-scheduler
NAME ENDPOINTS AGE
prom-prometheus-operator-kube-scheduler 192.168.2.10:10251,192.168.2.11:10251 23h
...
然后我就开始检查Prometheus的ServiceMonitor的相关配置 ,这个是关系到Prometheus是否能自动发现这个Target的,
我对比了其他的组件的ServiceMonitor也没有发现什么问题!这就比较懵逼,难道是这2个组件的/metrics端口没起来?
于是顺着这个思路我去查了宿主机上相应的进程以及端口情况!
终于发现问题所在,在kubernetes1.17.8版本之前,Kube-Scheduler、Kube-Controller-Manager的10251和10252 由于走的是HTTP协议,属于insecure非安全端口,1.17.8版本之后默认是不启用HTTP协议端口
详情可以参考相关PR以及CHANGELOG
github PR #93208
github PR#92720
Changelog since v1.17.8
https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.17.md#changelog-since-v1178
Kubeadm: add the deprecated flag –port=0 to kube-controller-manager and kube-scheduler manifests to disable insecure serving. Without this flag the components by default serve (e.g. /metrics) insecurely on the default node interface (controlled by –address). Users that wish to override this behavior and enable insecure serving can pass a custom –port=X via kubeadm’s “extraArgs” mechanic for these components. (#92720, @neolit123) [SIG Cluster Lifecycle]
现在问题找到了,那就得看如何解决
- 启用
HTTP协议端口10251和10252 - 禁用启用
HTTP协议端口10251和10252,启用HTTPS协议端口10259和10257
考虑到Prometheus Operator的Helm 安装默认启用的还是10251和10252,本着改动最小的原则,启用HTTP协议端口10251和10252 ,同时启用HTTPS协议端口10259和10257
现在方案定好了,那就是如何改?
我们知道Kube-Scheduler、Kube-Controller-Manager是以Static Pod形式运行,那就需要我们在特定路径/etc/kubernetes/manifests/下配置yaml文件
ls /etc/kubernetes/manifests/
kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
删除启动命令--port=0配置项,重建Pod,
建议在高可用集群环境下,先对组件所在Node 进行drain操作,滚动更新Pod
Kube-Proxy
kube-proxy的target发现失败,是由于kube-proxy的/metrics绑定的监听地址默认是127.0.0.1,导致没法被Prometheus抓取
kube-proxy是以DaemonSet的形式运行在集群里,需要改ConfigMap,滚动重建Pod
...
# 原先的配置
metricsBindAddress: 127.0.0.1:10249
...
# 修改后的配置
metricsBindAddress: 0.0.0.0
metrics-port: 10249
...
监控外部etcd集群
添加一个自定义监控的步骤也是非常简单
- 第一步建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项
- 第二步为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象
- 第三步确保 Service 对象可以正确获取到 metrics 数据
etcd证书
对于 etcd 集群一般情况下,为了安全都会开启 https 证书认证的方式,所以要想让 Prometheus 访问到 etcd 集群的监控数据,就需要提供相应的证书校验。
由于我这边etcd是以二进制形式部署,需要我们到相应目录下,找到证书,可以查看etcd进程运行的参数找到
...
--etcd-cafile=/etc/ssl/etcd/ssl/ca.pem --etcd-certfile=/etc/ssl/etcd/ssl/node-node1.pem --etcd-keyfile=/etc/ssl/etcd/ssl/node-node1-key.pem
...
TMPDIR=$(mktemp -d)
cp /etc/ssl/etcd/ssl/* $TMPDIR
cd $TMPDIR
mv ca.pem etcd-ca
mv node-node2.pem etcd-client
mv node-node2-key.pem etcd-client-key
kubectl -n monitoring create secret generic etcd-client-cert --from-file=/etc/ssl/etcd/etcd-ca --from-file=/etc/ssl/etcd/etcd-client --from-file=/etc/ssl/etcd/etcd-client-key
然后将上面创建的 etcd-client-cert 对象配置到 prometheus 资源对象中,直接更新 prometheus 资源对象即可:
kubectl edit prometheus prom-prometheus-operator-prometheus -n monitoring
...
replicas: 2
secrets:
- etcd-client-cert
...
验证3个文件是否以Secret的形式挂载进Prometheus
kubectl exec -it prometheus-prom-prometheus-operator-prometheus-0 -n monitoring -- /bin/sh
/prometheus $ ls /etc/prometheus/secrets/etcd-client-cert/
etcd-ca etcd-client etcd-client-key
修改ServiceMonitor
新增tlsConfig部分配置
...
port: http-metrics
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-client-cert/etcd-ca
certFile: /etc/prometheus/secrets/etcd-client-cert/etcd-client
keyFile: /etc/prometheus/secrets/etcd-client-cert/etcd-client-key
...
修改Service及Endpoints
删除 Service 配置文件中Selector 部分配置,因为有这部分配置会导致手动新增的endpoints配置,会因为endpoints controller根据label去匹配endpoints,匹配到空之后,覆盖手动新增的endpoints配置
...
subsets:
- addresses:
- ip: 192.168.2.11
- ip: 192.168.2.12
- ip: 192.168.2.13
ports:
- name: http-metrics
port: 2379
protocol: TCP
...
helm upgrade
prometheusSpec:
secrets:
- etcd-client-cert
kubelet:
serviceMonitor:
https: true
kubeControllerManager:
endpoints:
- 192.168.2.10
- 192.168.2.11
kubeScheduler:
endpoints:
- 192.168.2.10
- 192.168.2.11
kubeEtcd:
endpoints:
- 192.168.2.11
- 192.168.2.12
- 192.168.2.13
serviceMonitor:
insecureSkipVerify: true
scheme: https
caFile: "/etc/prometheus/secrets/etcd-client-cert/etcd-ca"
certFile: "/etc/prometheus/secrets/etcd-client-cert/etcd-client"
keyFile: "/etc/prometheus/secrets/etcd-client-cert/etcd-client-key"
helm install -f override.yaml --name prom stable/prometheus-operator
创建完成后,隔一会儿去 Prometheus 的 Dashboard 中查看 targets,便会有 etcd 的监控项了: