Kubernetes优雅进行Node的Cluster-Autoscaler扩缩容
原文链接:https://medium.com/scout24-engineering/cluster-overprovisiong-in-kubernetes-79433cb3ed0e
Cluster-Autoscaler
cluster-autoscaler是Kubernetes Github组织的一部分,但它是一个纯粹的可选工具。您需要像常规部署一样将其部署到群集并对其进行配置,以便它可以查找和管理您的节点组(如果是AWS,则为Autoscaling组)。cluster-autoscaler将开箱即用:
- 如果pod处于暂挂状态,则向节点组添加其他节点
- 删除未充分利用一段时间的节点(警戒线和漏极节点,然后从节点组中删除它们)。
嗯,这听起来很棒!但容器的一个很好的特性是它们的启动速度比VM快得多,对吧?在其默认配置中使用cluster-autoscaler时,您将有一些缓慢且不可预测的缩放行为。只有当pod进入暂挂状态时,cluster-autoscaler才会通过添加节点做出反应。由于EC2实例可能需要几分钟才能启动并准备好运行pod,因此如果您运行对此类扩展延迟敏感的服务,则这不是理想情况。我们怎么解决这个问题?
虽然cluster-autoscaler有替代方案([ 1 ],[ 2 ]),但我们希望继续使用Kubernetes社区提供的最常用解决方案。事实证明,有一种非常优雅的方式来对Node进行扩缩容,以便它总是预留一些动态缓冲区资源,以避免需要扩容的pod进入Pending状态几分钟。
Pod Priority
Pod Priority和Preemption是Kubernetes功能,允许您为pod分配优先级。简而言之,这意味着当群集资源不足时,它可以抢占(驱逐)优先级较低的pod,以便为等待安排的更高优先级的pod腾出空间。使用pod优先级,我们可以运行一些虚拟pod来保留集群中的额外空间,只要“真正的”pod需要运行就会释放。用于预订的吊舱理想情况下不应该使用任何资源,而只是坐在那里什么都不做。您可能听说过Pause容器已经在Kubernetes中用于共享namespace、network网络栈、PID Namespace,Pause容器的一个属性是它主要只是调用暂停系统调用,这意味着“睡眠直到收到信号”。
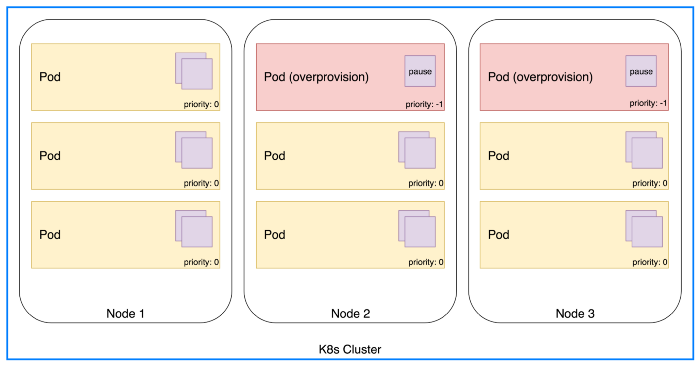
常规Pod和过度配置的Pod
总而言之,我们可以在群集中运行一堆Pause容器,其唯一目的是保留空间以欺骗cluster-autoscaler过早添加额外节点。由于这些Pod的优先级低于常规Pod,因此一旦资源变得稀缺,它们就会从群集中被驱逐。Pause容器将进入Pending状态,进而触发cluster-autoscaler以增加node节点。总的来说,这是一种非常优雅的方式,可以在群集中始终拥有动态缓冲区。
---
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: reserve-resources
image: k8s.gcr.io/pause
resources:
requests:
#According to your cluster environment config
cpu: 4
memory: 8Gi
为什么要运行只包含Pause容器的Pod?
运行不执行任何操作的pod的想法起初看起来有点奇怪,但这种方法有一个很大的优势。我们可以肯定我们实际上可以运行其他pod,缓冲区不仅仅是通过某些算法计算生成,例如可选择的autoscaler。除了CPU和内存之外,还有其他资源可以用尽,比如我们使用Amazon VPC CNI插件时的IP地址。通过运行实际的pod,我们可以确定缓冲区实际上可以被其他业务的pod使用。
缩放缓冲区
现在,这已经很好地工作但是如何扩展过度配置部署本身的大小呢?今天,集群可能包含10个工作节点,但在几个月内它可以增长到100个节点或更多节点。如果缓冲区空间与簇大小成比例增长,那将是理想的。事实证明,有一种解决方案正是名为cluster-proportional-autoscaler。您可以将其应用于K8s部署并指定coresPerReplica值。这意味着您的部署的一个副本弥补了整个群集的指定数量的核心。
举一个具体的例子:
如果您的部署使用4个CPU内核并且您希望确保10%的缓冲区,则需要将coresPerReplica设置为40.这意味着对于整个群集大小的每40个核心,将有一个Pod副本(4个核心)。
---
kind: ConfigMap
apiVersion: v1
metadata:
name: overprovisioning
namespace: kube-system
data:
linear: |-
{
"coresPerReplica": 40
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning-autoscaler
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: overprovisioning-autoscaler
template:
metadata:
labels:
app: overprovisioning-autoscaler
spec:
containers:
- image: k8s.gcr.io/cluster-proportional-autoscaler-amd64:1.1.2
name: autoscaler
command:
- /cluster-proportional-autoscaler
- --namespace=kube-system
- --configmap=overprovisioning
- --target=deployment/overprovisioning
- --logtostderr=true
- --v=2
serviceAccountName: cluster-proportional-autoscaler
10%过度配置缓冲区(RBAC为简洁而省略)
参考文档
https://github.com/kubernetes-incubator/cluster-proportional-autoscaler
https://wemp.app/posts/57abb519-8309-4373-b175-2620d54c33fe