最近在Slack的prometheus 告警通道经常收到etcdHighNumberOfFailedGRPCRequests 这个条告警信息
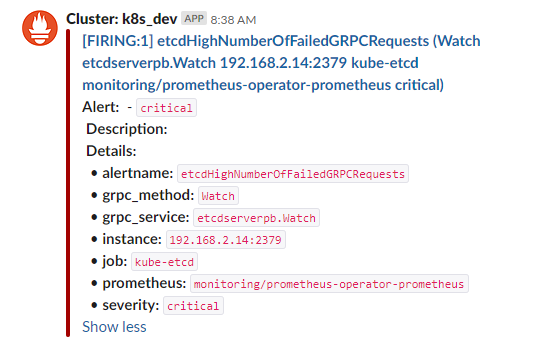
登录到这个机器上查看log 相近时间的日志也没看到什么异常信息
就只能求助google 应该有人也会碰到一样的问题
查到redhat的bugzilla下的一个issus
https://bugzilla.redhat.com/show_bug.cgi?id=1701154
以及openshift下一个PR
https://github.com/openshift/cluster-monitoring-operator/pull/340/files#diff-1
提供一个短期解决方案
移除这条etcd告警的rules
由于Helm安装的Prometheus-operator 需要在template里找到相应的模板位置
.../templates/prometheus/rules/etcd.yaml
...
44 - alert: etcdHighNumberOfFailedGRPCRequests
45 annotations:
46 message: 'etcd cluster "`}}": `}}% of requests for `}} failed on etcd instance `}}.'
47 expr: |-
48 100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*", grpc_code!="OK"}[5m])) BY (job, instance, grpc_service, grpc_method)
49 /
50 sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) BY (job, instance, grpc_service, grpc_method)
51 > 1
52 for: 10m
53 labels:
54 severity: warning
55 - alert: etcdHighNumberOfFailedGRPCRequests
56 annotations:
57 message: 'etcd cluster "`}}": `}}% of requests for `}} failed on etcd instance `}}.'
58 expr: |-
59 100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*", grpc_code!="OK"}[5m])) BY (job, instance, grpc_service, grpc_method)
60 /
61 sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) BY (job, instance, grpc_service, grpc_method)
62 > 5
63 for: 5m
64 labels:
65 severity: critical
...
然后
root@k8s-master-1:~/k8s_manifests/helm-prometheus-operator# helm upgrade prometheus-operator .